
Please note that this blog is archived and outdated. For the most current information click here!
Software Estimates: Traditional vs. Scientific Accuracy
One of the first questions asked when undertaking any type of project is usually how much will it cost? It's a reasonable question to ask, before making a decision it's only natural to want all the facts at hand. There are some industries where this has become the norm - the painting and construction industries come to mind. However, this is vastly different in the software industry.
This article is designed to unpack the software estimation process and the different approaches used in the industry.
The industry
Generally the next follow up question asked is why can’t you tell me exactly how long it will take? Software differs to other industries as it deals predominantly with unknowns. Every piece of software is designed to be different in one way shape or form, otherwise there is no unique value proposition. Couple that with the fact that technology continues to improve rapidly, with a new ‘industry standard’ emerging every couple of years and it becomes incredibly unlikely that a software developer will build the same application, the same way, twice.
The problem with software estimates
There is a societal problem when it comes to estimating work. In many instances the cheapest estimate wins the work. This wouldn't be an issue provided the estimate was accurate and did not impact the quality of the project. So if the project blows out or the quality is not up to scratch, does the blame rest with the development company for low-balling the project or the customer that chose the cheapest option? With a greater knowledge and understanding of the estimations process, we can move away from this cycle.
When to estimate
There are many competing lines of thought here with different strategies recommended based on which phase the project is in. For the purpose of this article we'll break a project into the common stages; ideating, scoping and developing.
Ideating
Before the project is properly scoped it is still in an ideation phase. This means all the requirements are not yet known.
Bracketing
This is one of the more popular approaches to undertake when the software is at such an early stage. Based on the software developer's prior experiences and gut feeling they may give a broad bracket as to the length of time based on a few central requirements.
Historical comparison
If the complexity and size of the project sounds similar to a past project than the estimate given may simply be the time it took to build the past project.
The problem with giving an estimate this early on in the process is that there are so many unknowns. Generally, the client will budget and set their expectations based on a very early stage estimate (if it has been given). What happens when the scope is unpacked and the initial estimate is inaccurate? It creates tension and impacts the trust between the software development company and the customer.
No development estimate
WorkingMouse's preferred approach to estimating a project before it is scoped is simple. We don't. We can estimate the time it will take to properly scope the project based on its complexity but we do not have enough information to estimate development time.
Scoping
T-Shirt sizes
This exercise is one of relativity. By marking functionality as XS, S, M, L, XL (and so on) we can group together similar pieces of functionality. It's generally much faster than traditional time based estimates.
Once the tickets are grouped, estimation values can be put to each group. For example, an XS ticket may on average take 2 hours to complete. In a short space of time, the development team and product owner can start gauging the relative size of the application. Keep in mind, the estimate can still be inaccurate at this stage.
Fibonacci estimations
As mentioned above, software estimations are inherently quite difficult. The Fibonacci-type approach to estimations tries to simplify things. It is based on the theory that the bigger something is, the less precise we can be. It is reasonable to assume that a small piece of functionality can be estimated down to the hour. However when we start looking at bigger pieces of functionality, for example complex API integrations, which have a high degree of complexity and difficulty, we cannot be that precise. Something may be estimated to take a week or 3 days but it would be bold and ultimately unwise to estimate that it will take 1 week, 1 day and 2 hours.
It is recommended to wait until the end of scope, once all the immediate functionality is known to hold an estimations session. Without stakeholders aligned on the acceptance criteria of each piece of functionality and its impact across the wider application, it is difficult to ensure the accuracy of the estimates.
Planning poker
This is a slightly different way of running the Fibonacci approach to estimating. Everyone is given a set of cards with lengths of time. It's designed to ensure that one team members estimate (the first to speak) doesn't influence other team members estimates.
Development
During a planning session
During development, planning sessions occur at the beginning of each iteration (or sprint). It gives the development team an opportunity to learn from earlier iterations. It also gives them an opportunity to feed learnings back into the estimations.
Let's say for example after two iterations a developer was able to leverage a React library more than initially anticipated. That might bring the estimates for some functionality down, allowing more to be completed during the iteration. On the other hand, there may be a complication that means certain functionality takes longer than initially expected. By elaborating on estimations during the planning session, the development team has the most recent information available to make an estimate.
Types of estimations
While all the techniques listed above are helpful, it's more important to distinguish between traditional estimations and how they've been refined to embrace a more scientific approach.
Traditional software estimations
These are quite simply estimates against functionality. By asking how long "X" will take and doing some simple addition, that will give you the traditional project estimate.
The issue with this approach is that it fails to capture a number of other factors that have a major impact on time. For example, it is unrealistic to believe that 100% of a developers day will be spent working on a project. There are planning meetings, morning huddles and company-wide meetings that impact productivity.
Scientific software estimations
By understanding and measuring the impact that other factors have on development time, we can be more scientific in our estimations. After running an experiment over a number of projects we found a few factors impacted development length. These factors will be addressed in more detail below.
Each of these factors have a multiplier based on the impact that they have on estimates. As mentioned above, a rushed project can detrimental to the quality of the application. It is absolutely necessary to take these factors into consideration in order to accurately set expectations.
Risk is the most complex factor to measure. As a general rule, some projects are riskier than others. So then, how do we capture risk? Our approach is to separate risk into two contributing factors; complexity and unfamiliarity. These are measured on a 1-5 scale for each piece of functionality. The higher the risk, the greater the estimate for that functionality.
What is the average estimate for a feature?
As mentioned earlier, it is notoriously difficult to estimate a software project before it is scoped. However, there are a range of learnings that can be made by looking at historical data for trends. To give you as much insight as possible, we’re sharing novel data, taken from past projects at WorkingMouse.
Table 1: Average size of past tickets at WorkingMouse
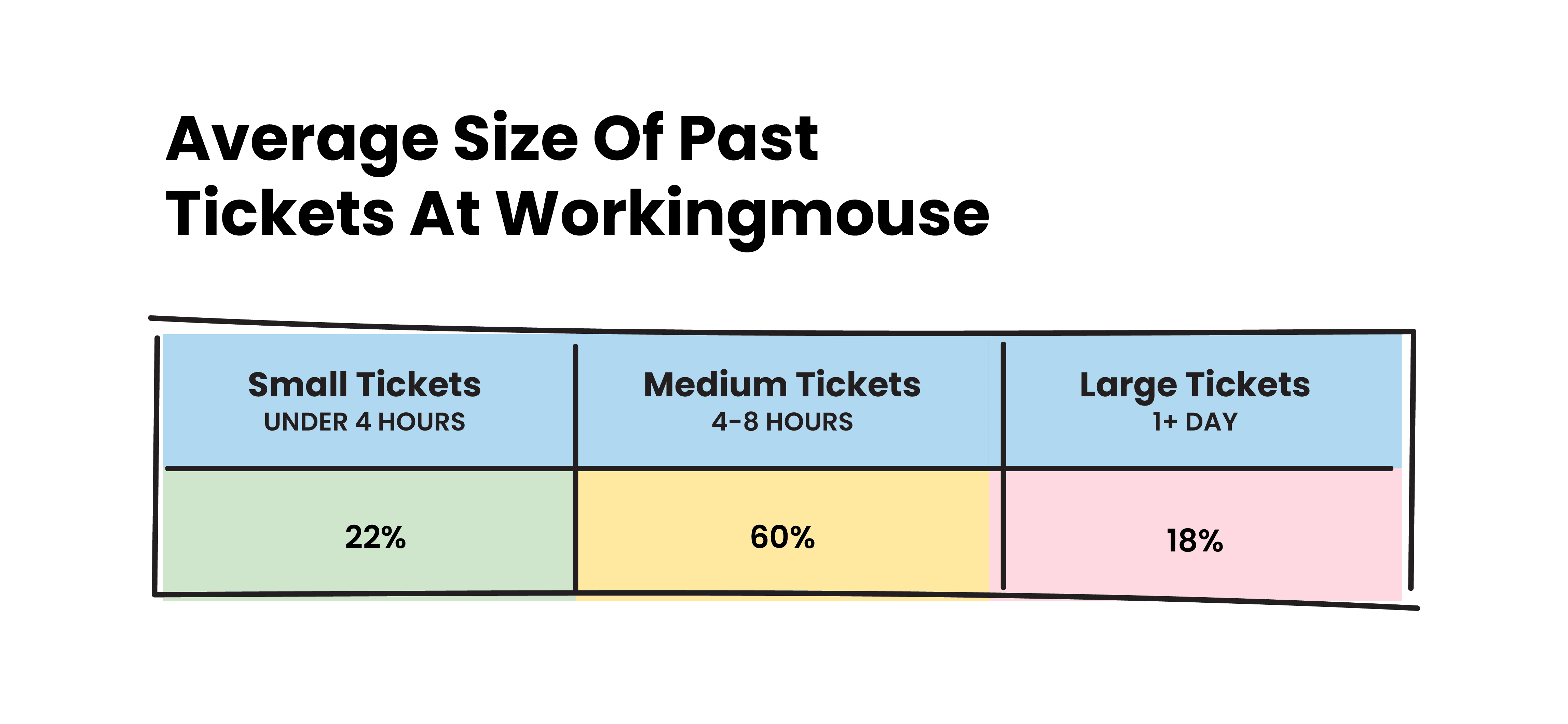
This table tells us a few things.
Firstly, there is risk in leaving tickets large (over 1+ day in length). It is common for developers and development agencies to break these tickets down into smaller, more manageable pieces. Rather than a single 2-day ticket which might encompass a few components, there is less risk in 3x 5-hour tickets that are smaller in size and more focused in functionality.
Secondly, there are minimal tickets that can be completed in under 4 hours. Between feature development, writing tests and releasing, it’s difficult to complete a ticket to a high quality in under 4 hours.
Finally, there is safety in the pack. This can be a result of sequence bias or the golden mean fallacy. The sequence bias is the likelihood that the prediction before will influence the prediction after. So, if the first few tickets are medium sized tickets, then the likelihood that the next ticket is also estimated as a medium ticket is raised. The golden mean fallacy is the perception that the truth lies somewhere in the middle. Hence the idea that the right estimate is somewhere between 4 and 8 hours in length.
How to increase the accuracy of a software estimate
The million-dollar question; how do we improve as an industry and increase the accuracy of software estimates?
This comes down to refining the way that we estimate. We approach this problem with the view that no matter what the solution is, it will never be perfect. But we can continue to try get closer and closer to perfection.

The best scientific formula we’ve created to date takes into consideration:
- Feature development,
- Testing,
- Allocation for other tasks,
- Discovery,
- Peer review,
- Delivery/releasing.
This article represents our current approach to software estimations. In the past these factors and the influence they have on estimates differed. It’s only through a mode of continuous learning that we can increase the accuracy of software estimates.
To summarise
If you’ve gotten this far, well done. While the science behind software estimations may not excite many, there is no question that they have a huge impact on the success of a project. Start with an inaccurate estimate and you’ll find yourself on the back-foot, often at the expense of quality.
My advice is to ask your development company how they approach the estimations process. If they’re willing to give a quote or estimate before the scope is fully fleshed out and agreed upon, that should be a red flag. Also ask about the allowances they have for necessary work that isn’t feature development.




